Ingest Pipeline for YT Transcripts
THE PROBLEM
A UK-based client was manually processing large volumes of unstructured content — transcripts, documents, and raw text — before it could be used downstream. Each file required manual review, formatting cleanup, metadata extraction, and storage preparation. As incoming data volume grew, the process broke down: it was slow, inconsistent, and impossible to scale without adding headcount.
🔧 WHAT I BUILT
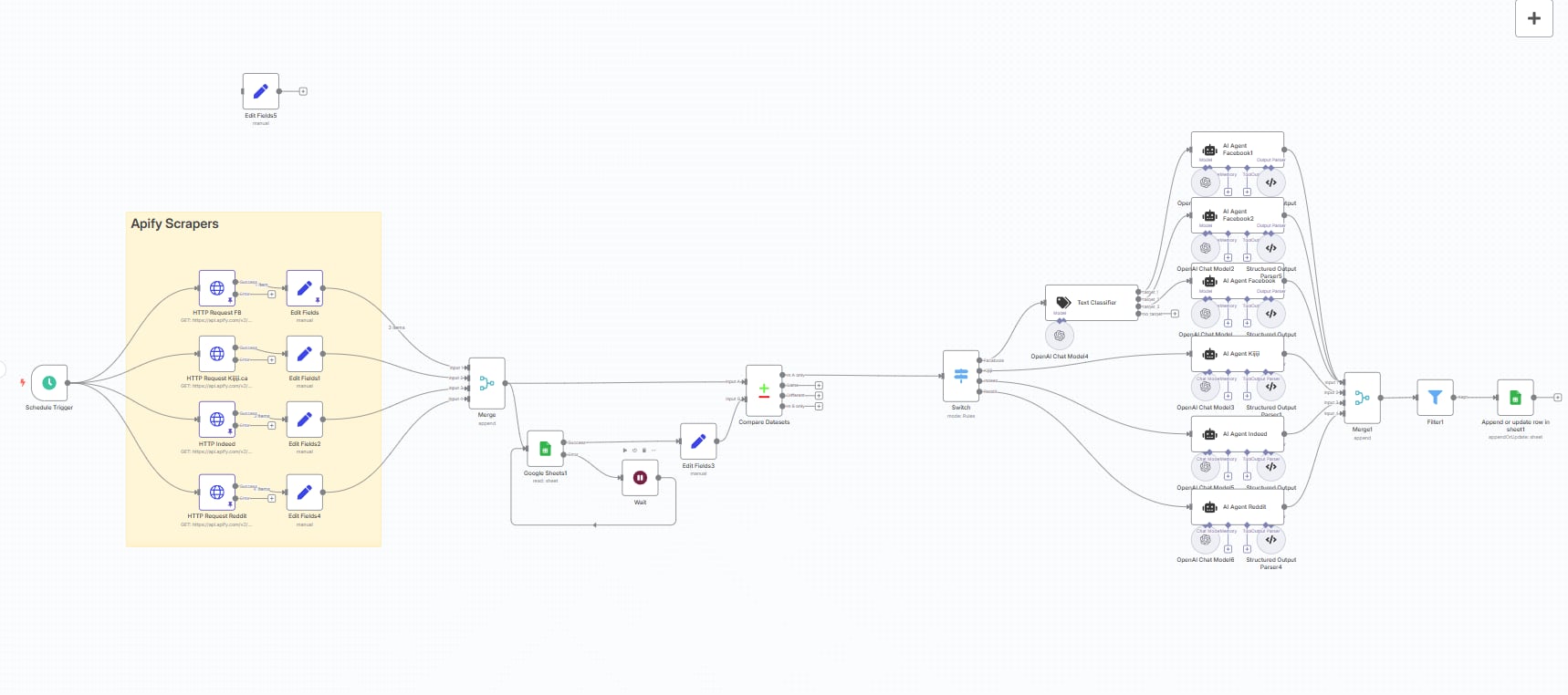
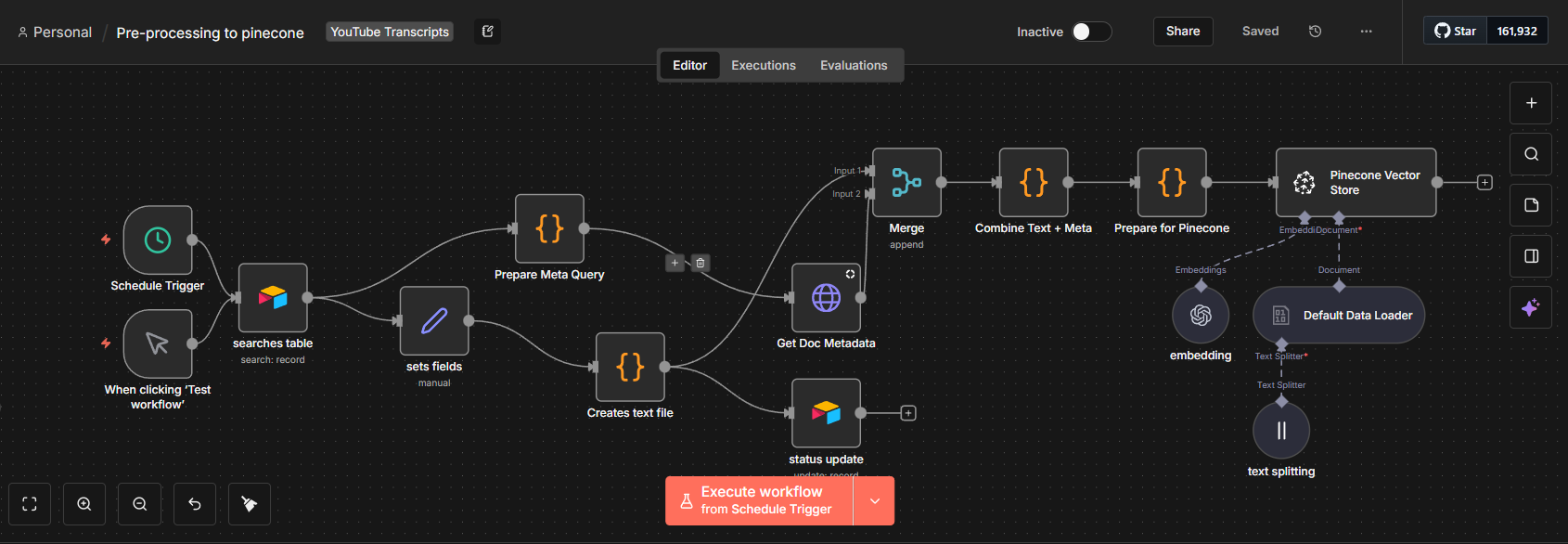
I designed and built a fully automated AI ingest pipeline in n8n that eliminated every manual step in the data intake process:
Automated document and transcript collection from configured sources (Google Sheets, direct uploads)
AI-powered cleaning and formatting using the OpenAI API — removing noise, fixing structure, and standardizing output
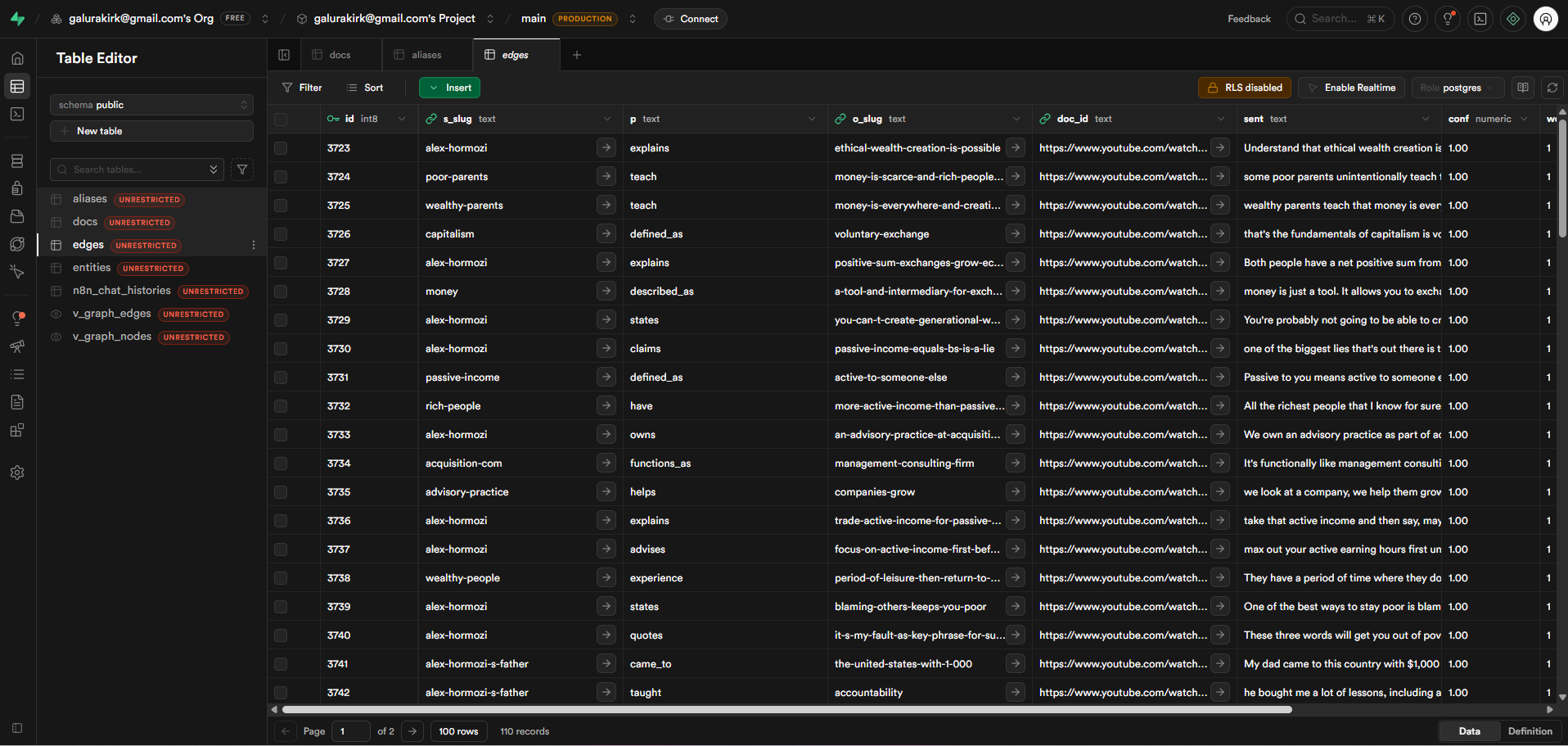
Metadata extraction layer that auto-generated doc_id, title, source URL, category, and topic keywords for each document
Validation and routing logic to handle edge cases — duplicate detection, malformed inputs, retry handling on failed API calls
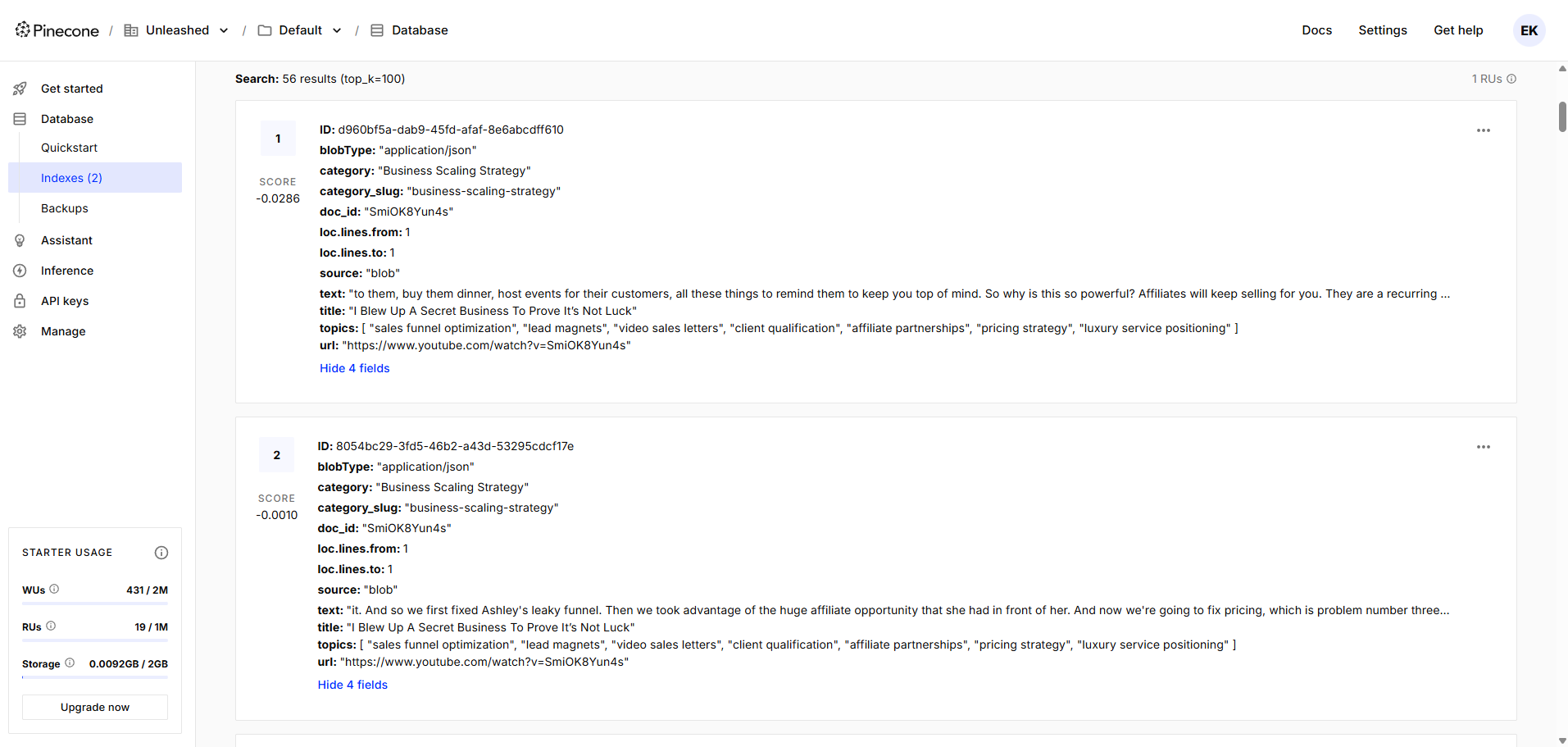
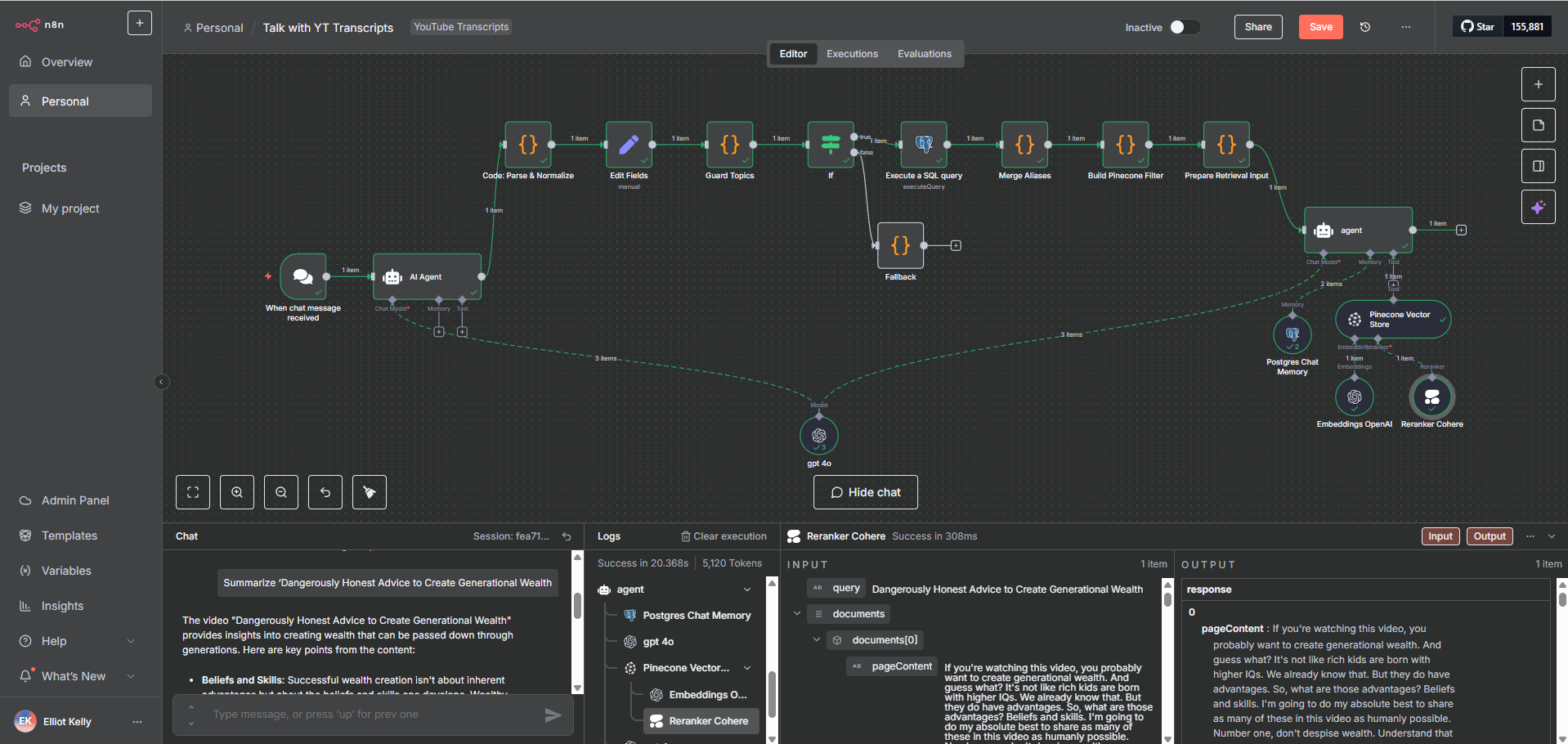
Structured output preparation feeding into downstream PostgreSQL and Pinecone storage
✅ THE RESULT
The pipeline fully automated what was previously a manual, multi-hour process per batch. The client could now ingest 1,000+ documents with zero manual intervention, with consistent structure and metadata across every record. Operational bottlenecks were eliminated, data quality improved measurably, and the pipeline established the foundation for the downstream RAG retrieval system built in Case Study 3.