Supabase for Metadata
🔴 THE PROBLEM
As AI pipeline complexity grew, storing and retrieving structured metadata alongside vector data became a bottleneck. Pinecone handles embeddings well, but relational metadata — document relationships, processing status, audit trails, and entity mappings — needed a separate, queryable layer. Without it, pipeline debugging, filtering, and downstream reporting were slow and error-prone.
🔧 WHAT I BUILT
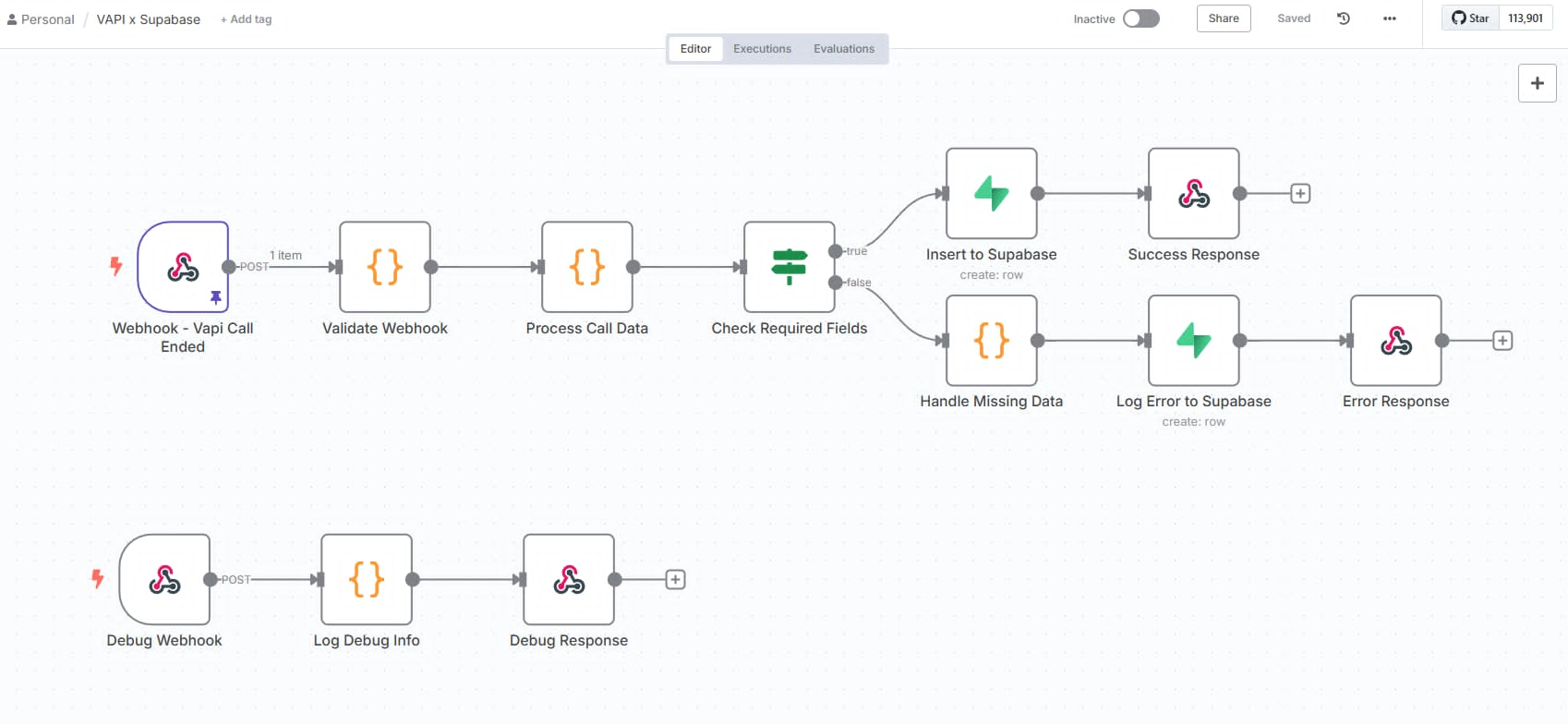
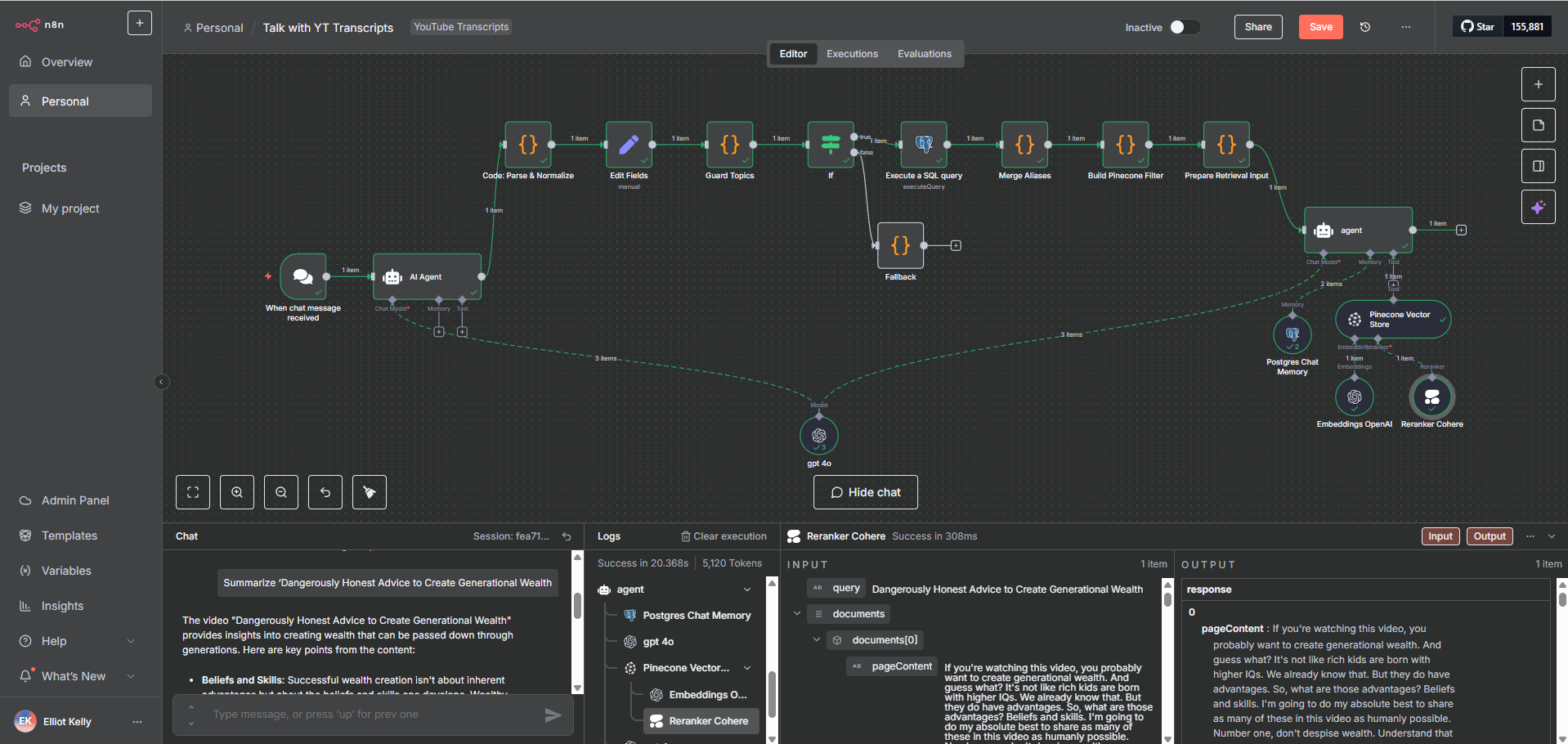
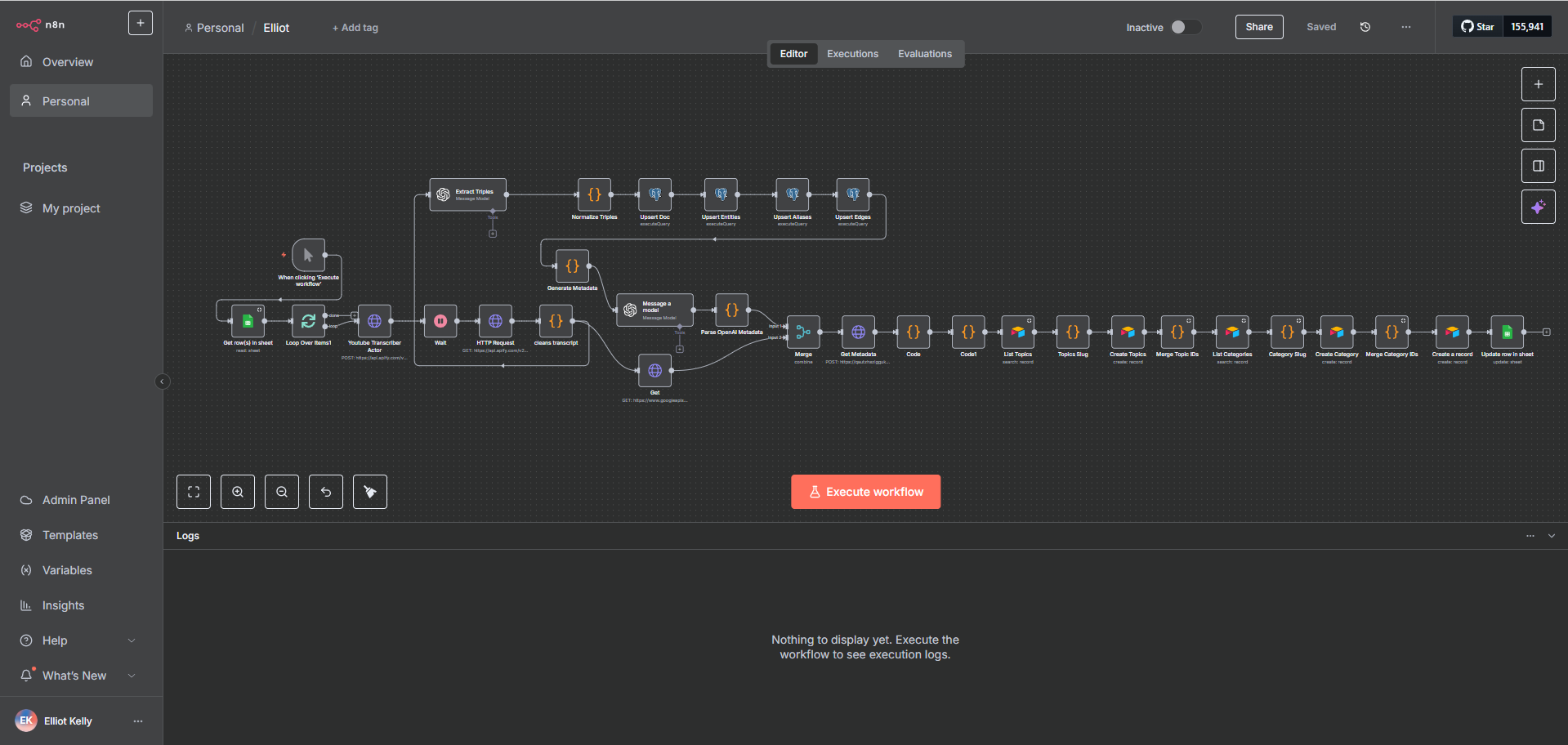
I designed a Supabase-backed metadata layer that works alongside Pinecone as a complementary structured data store:
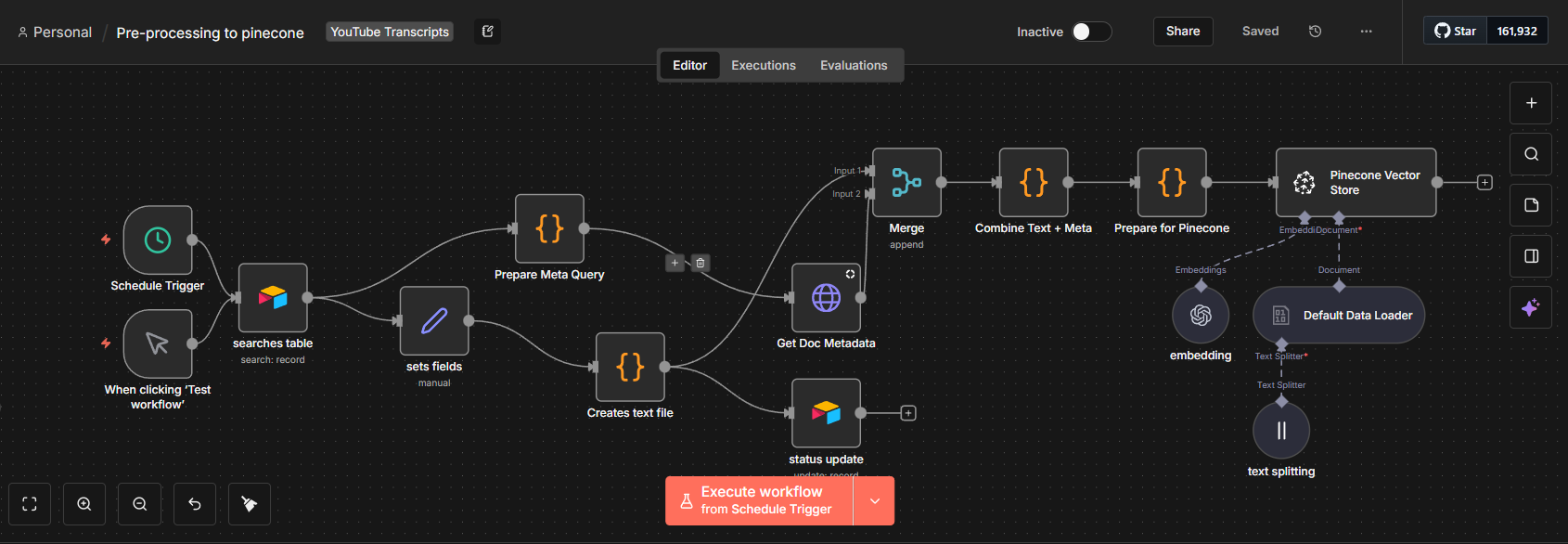
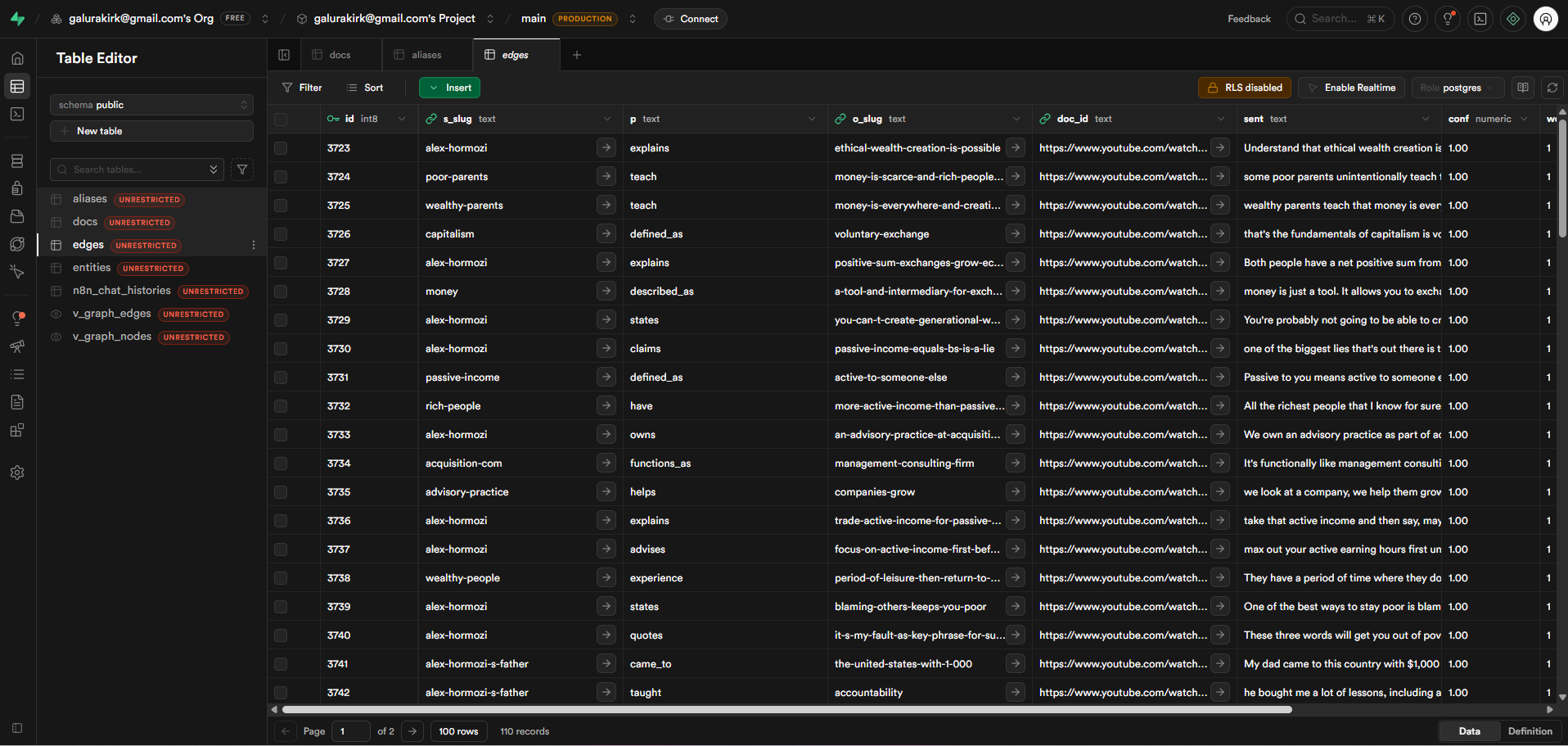
Automated metadata writes on every document processed — storing doc_id, source, category, processing status, timestamps, and chunk counts into structured Supabase tables
REST API integration between n8n and Supabase for real-time reads and writes without manual database access
Status tracking logic that updated records across pipeline stages — ingested, processed, embedded, failed — enabling easy monitoring and reprocessing of failed records
Entity and alias tables for Graph RAG enrichment, storing normalized subject–relation–object triples and their source mappings
✅ THE RESULT
The metadata layer gave the pipeline full observability — every document's journey through the system was tracked, queryable, and auditable. Debugging dropped from hours to minutes. The structured data also enabled smarter Pinecone filtering downstream, improving retrieval precision and reducing noise in AI responses.