Pinecone Vector Database
🔴 THE PROBLEM
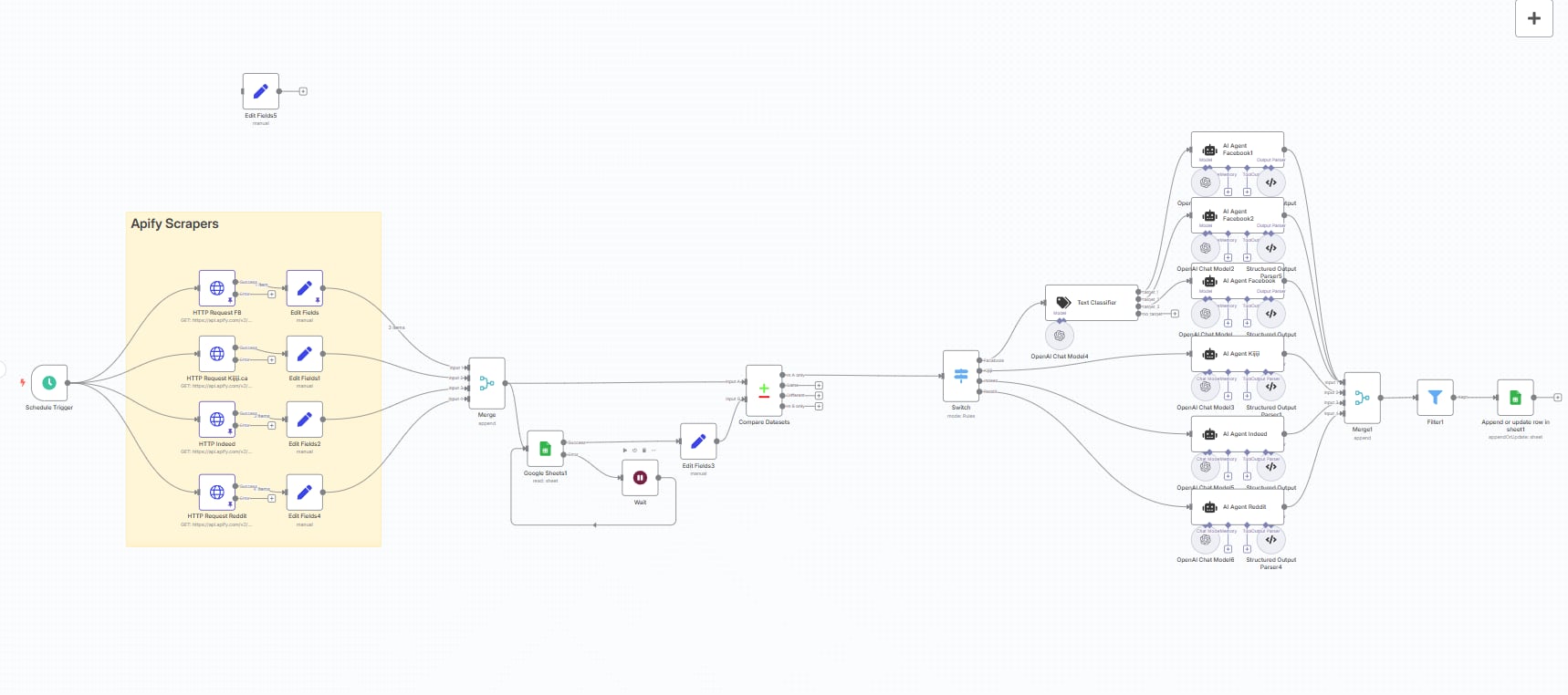
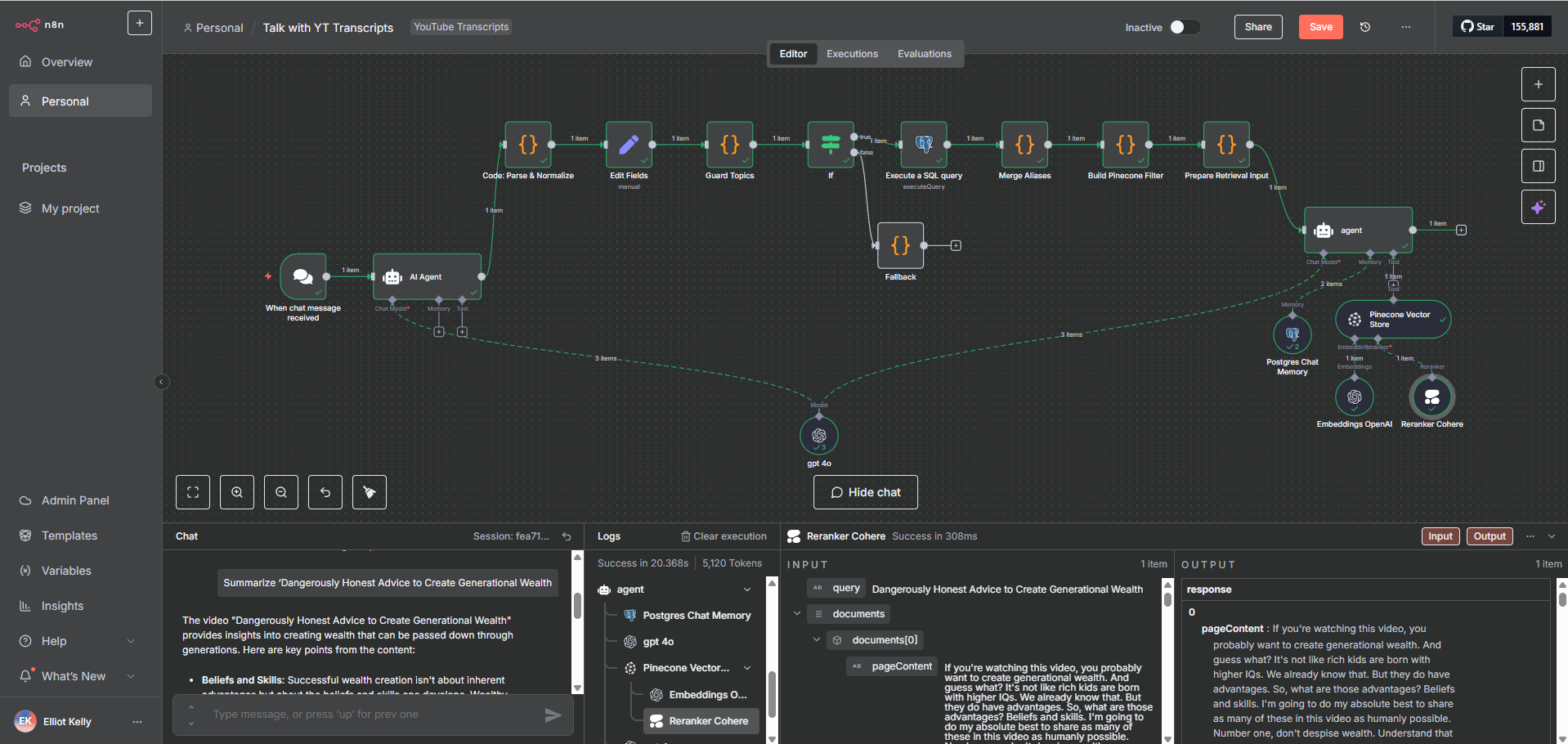
The client's knowledge base was growing rapidly across multiple content categories, topics, and document types. Without a deliberate vector database architecture, retrieval quality degrades as index size grows — results become noisy, filtering becomes unreliable, and query costs increase. The system needed a scalable Pinecone structure that could handle volume without sacrificing precision.
🔧 WHAT I BUILT
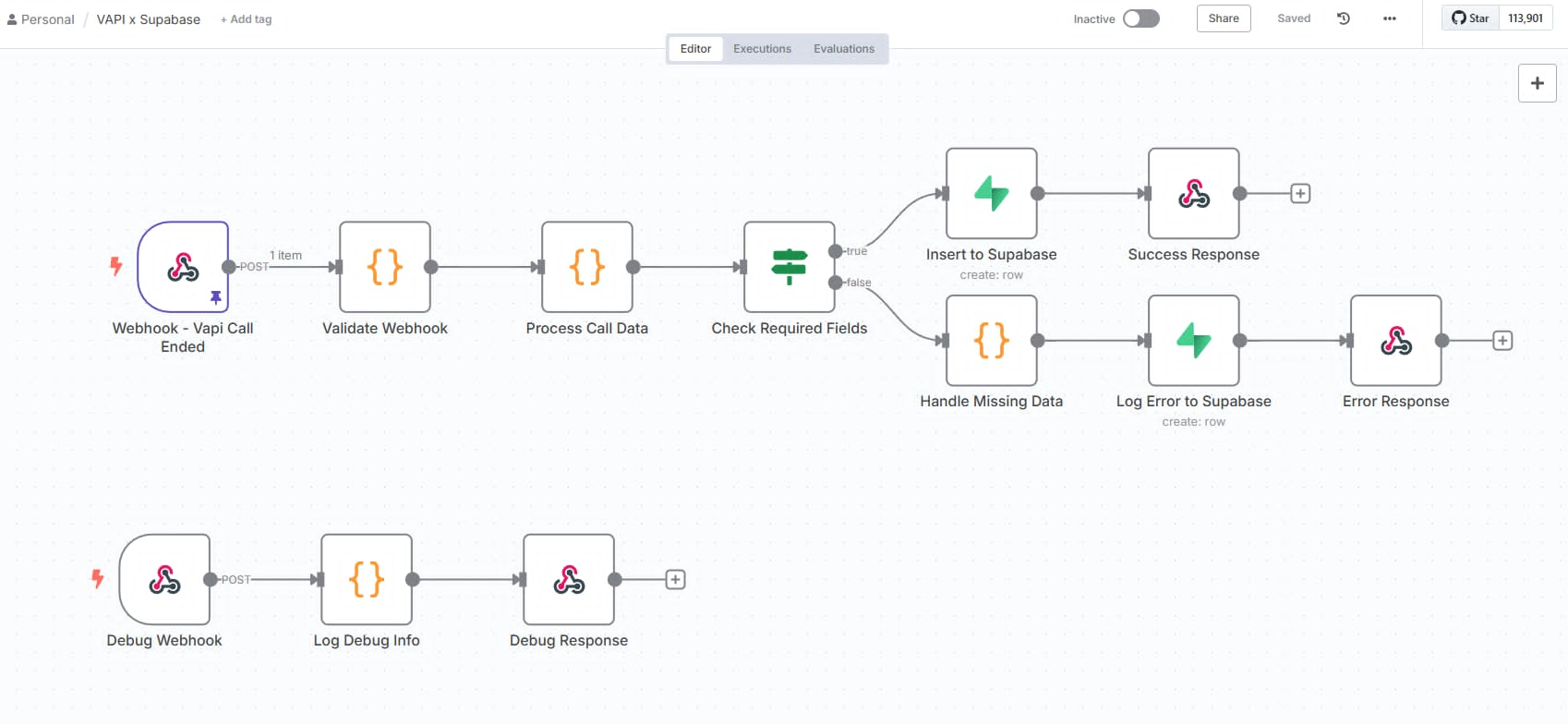
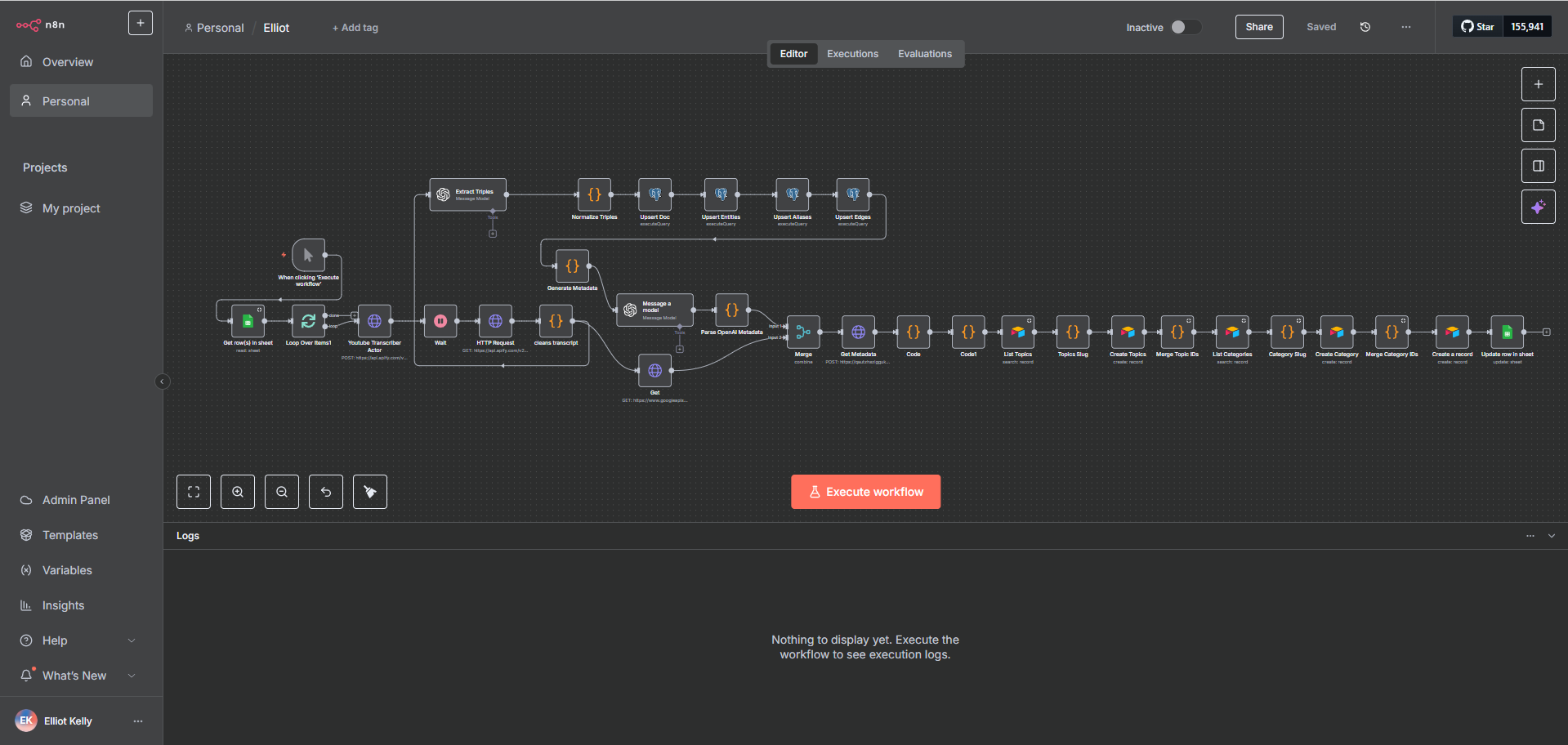
I designed and implemented the Pinecone index architecture and metadata schema to support accurate, filterable semantic retrieval at scale:
Namespace segmentation strategy to logically separate document categories, preventing cross-contamination in retrieval results
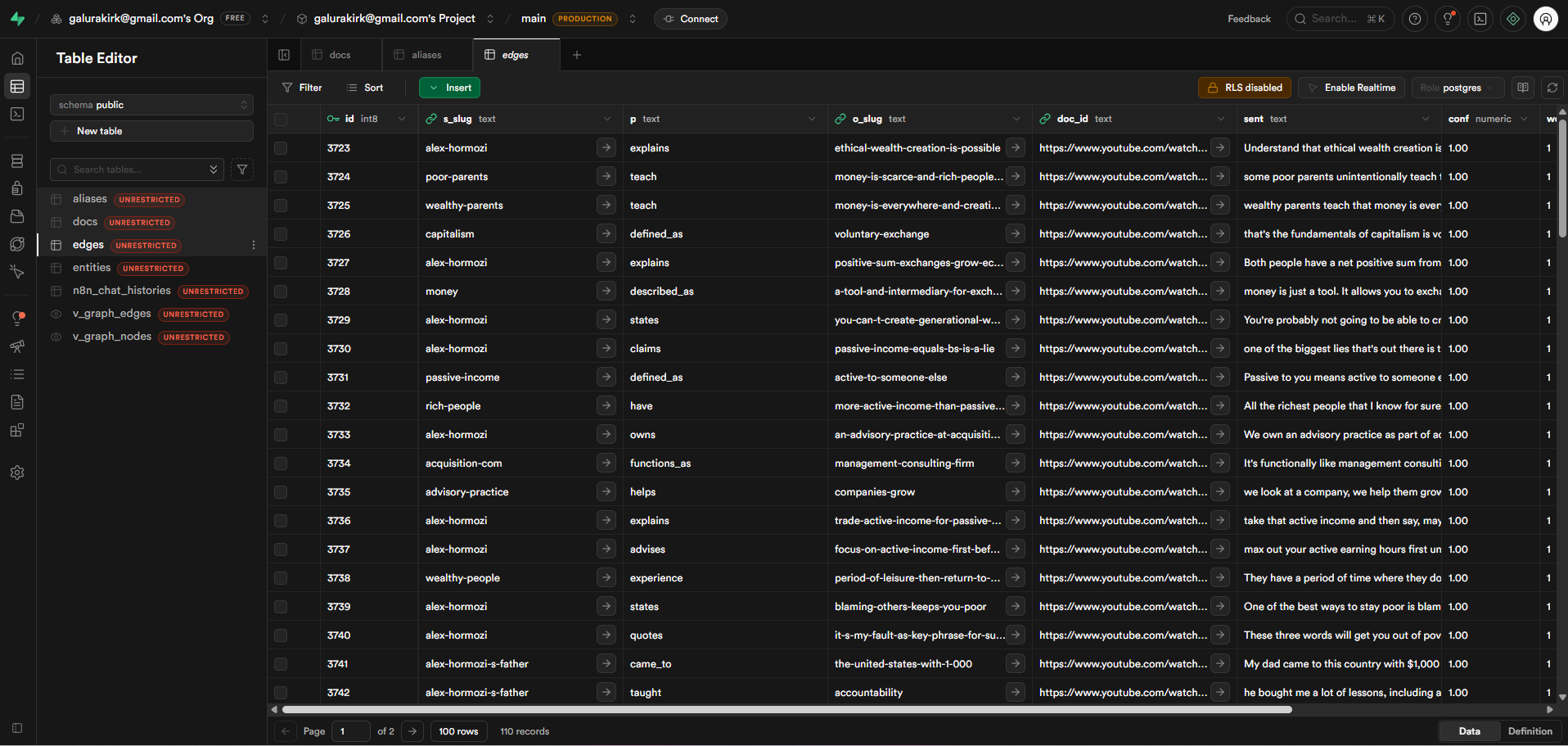
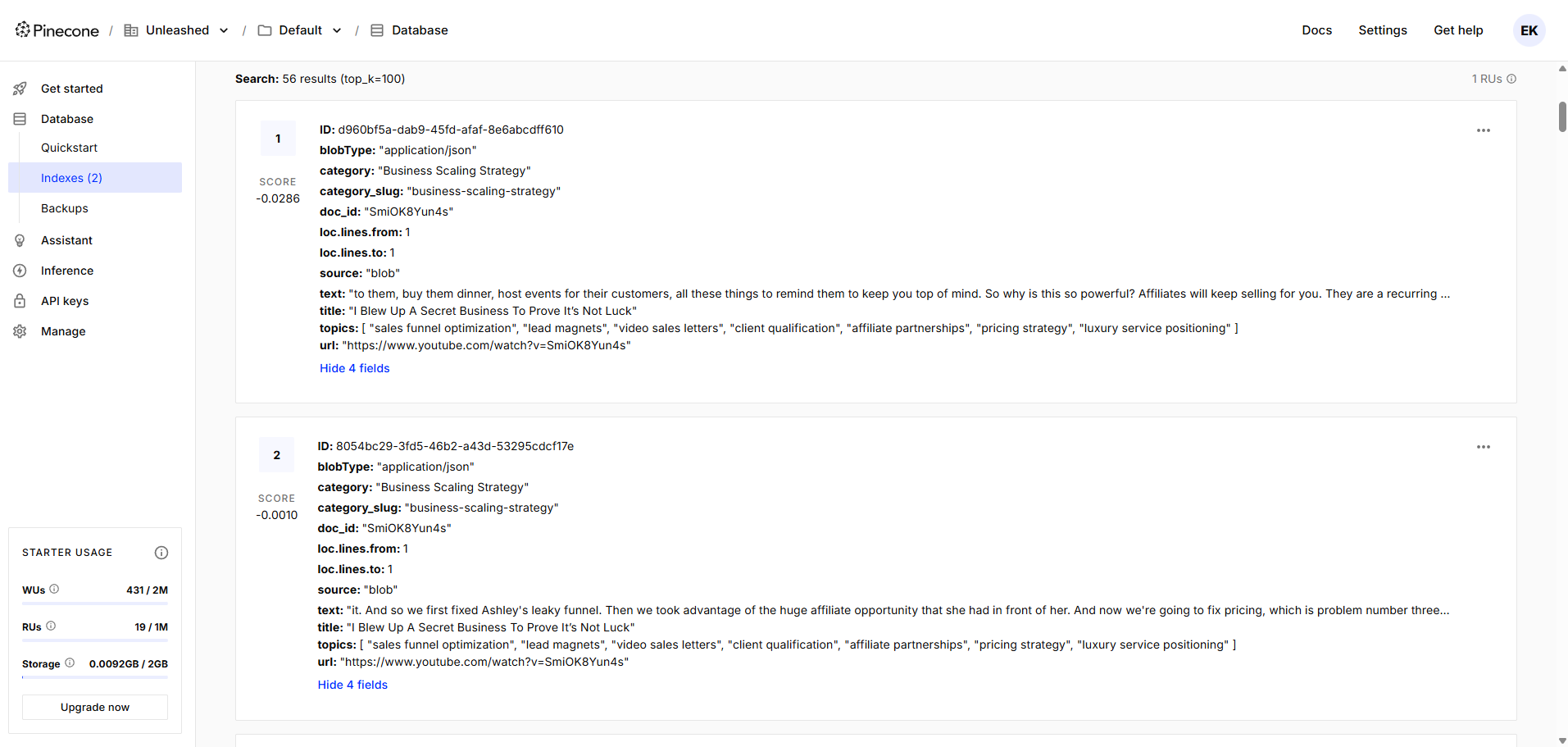
Metadata schema design — every vector stored with a consistent structure (doc_id, title, category, topic_keywords[], chunk_index, source_url) enabling compound filter queries
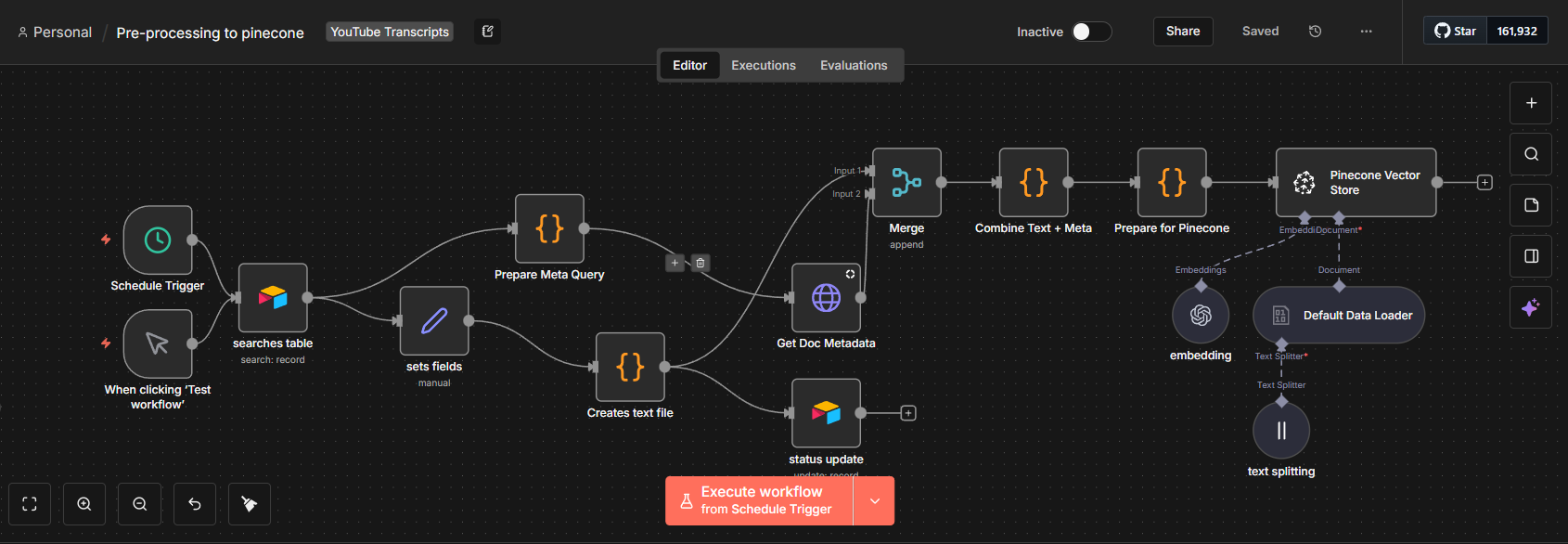
Embedding pipeline optimization — chunk sizing calibrated to balance context richness with embedding model token limits
Alias normalization feeding into metadata at upsert time, so varied phrasings of the same concept retrieve the same underlying content
Index monitoring and hygiene — duplicate detection, stale vector cleanup, and upsert idempotency to maintain index integrity over time
✅ THE RESULT
The structured index design enabled precise, low-noise retrieval even as the knowledge base scaled to thousands of documents. Compound metadata filters reduced irrelevant results significantly, and the alias normalization layer improved recall for varied user queries. The architecture became the backbone of the full RAG system described in Case Study 3.