Pre-processing to Pinecone
🔴 THE PROBLEM
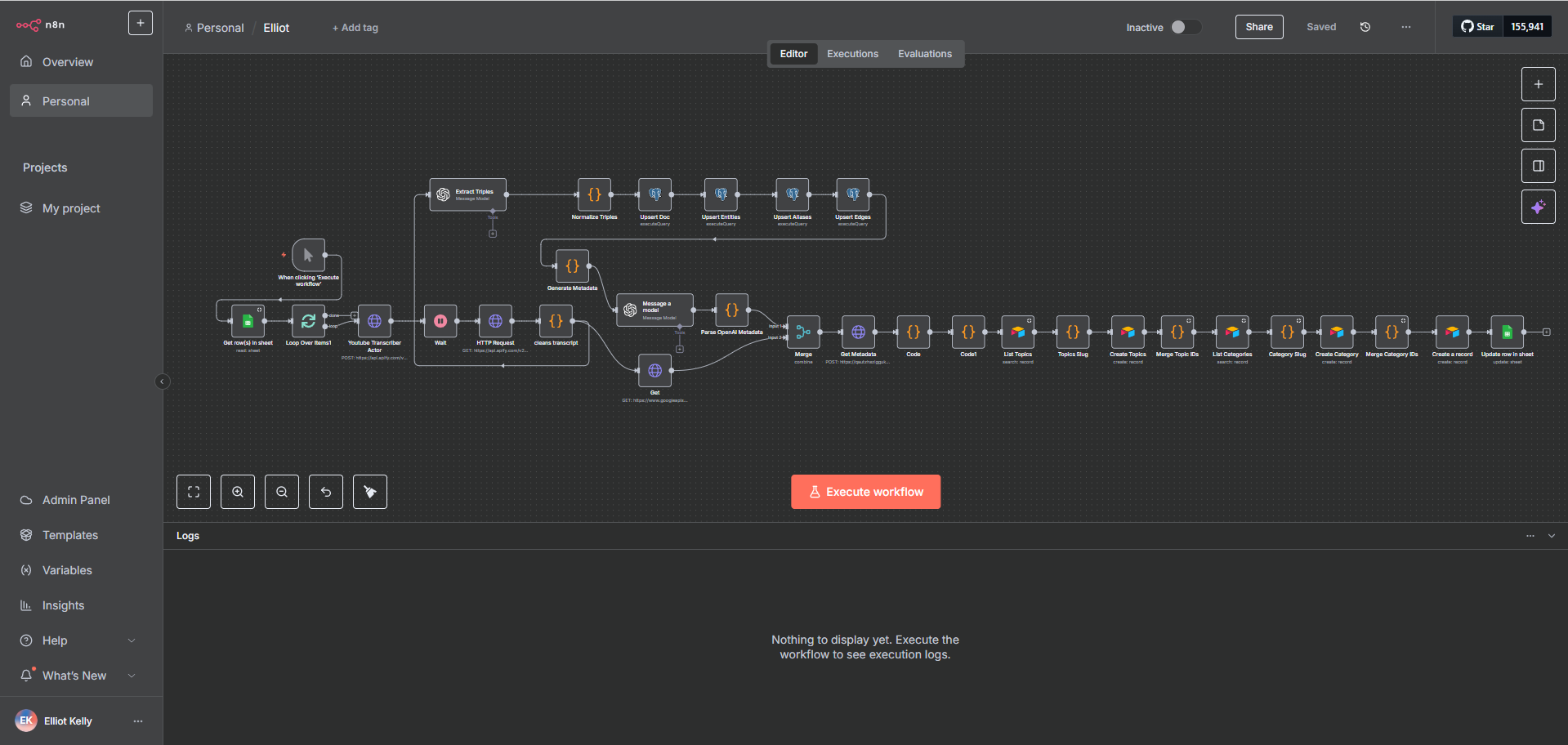
After ingesting raw content, the client had no scalable way to store or search it intelligently. Traditional keyword-based search returned poor results across large document sets, and there was no structured process for transforming cleaned text into AI-retrievable assets. The business needed a pipeline that could prepare data for semantic search at scale — consistently, automatically, and without manual oversight.
🔧 WHAT I BUILT
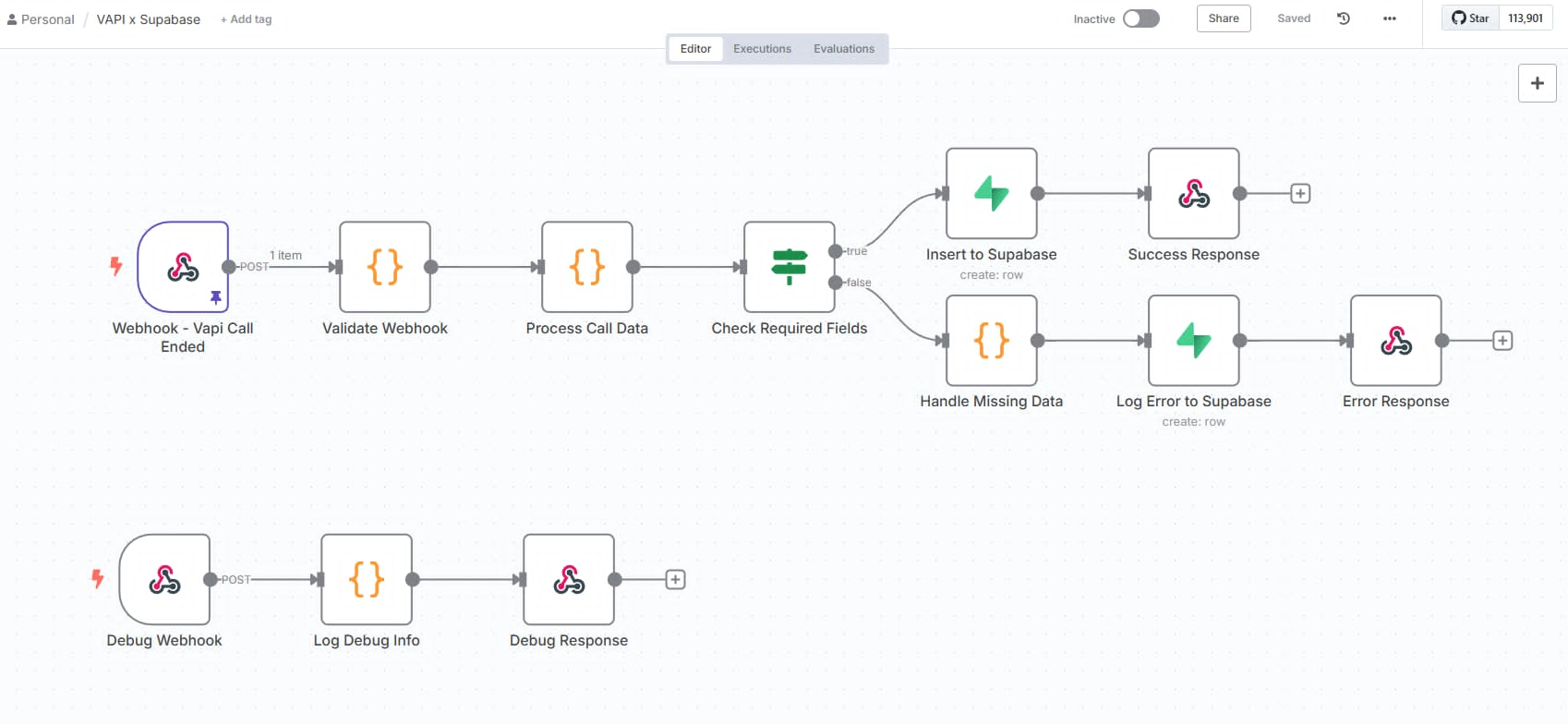
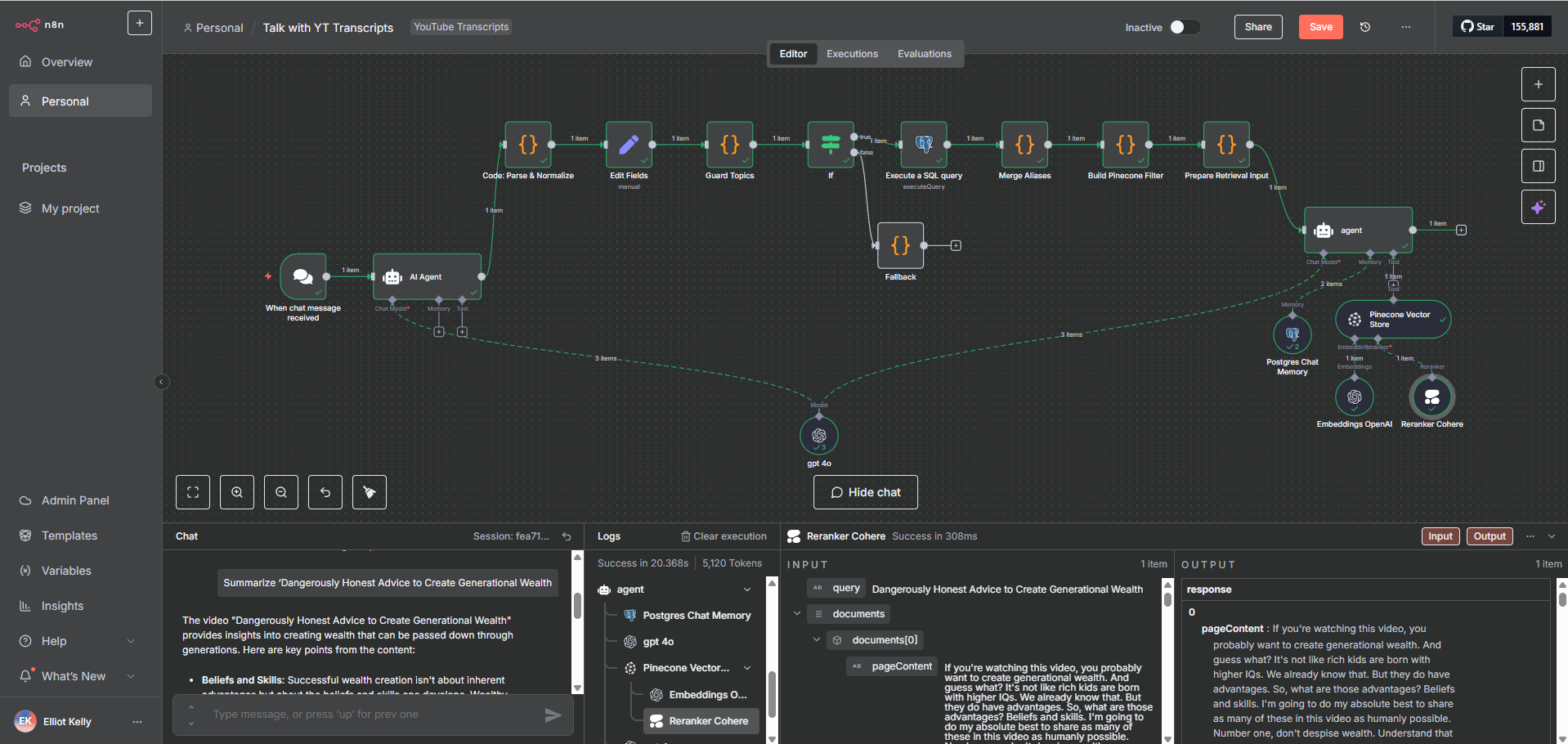
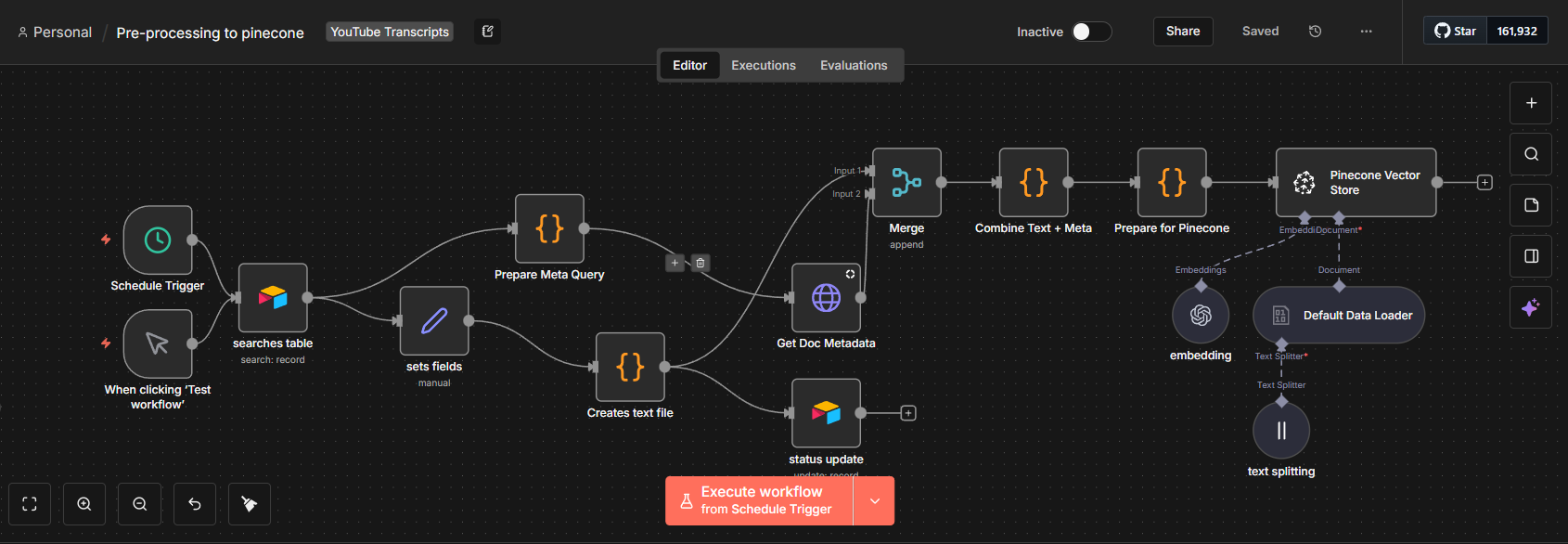
I built a pre-processing and vector storage workflow that transformed cleaned documents into searchable AI-ready knowledge assets:
Automated document chunking logic that split large texts into optimized segments, balancing retrieval accuracy with context window constraints
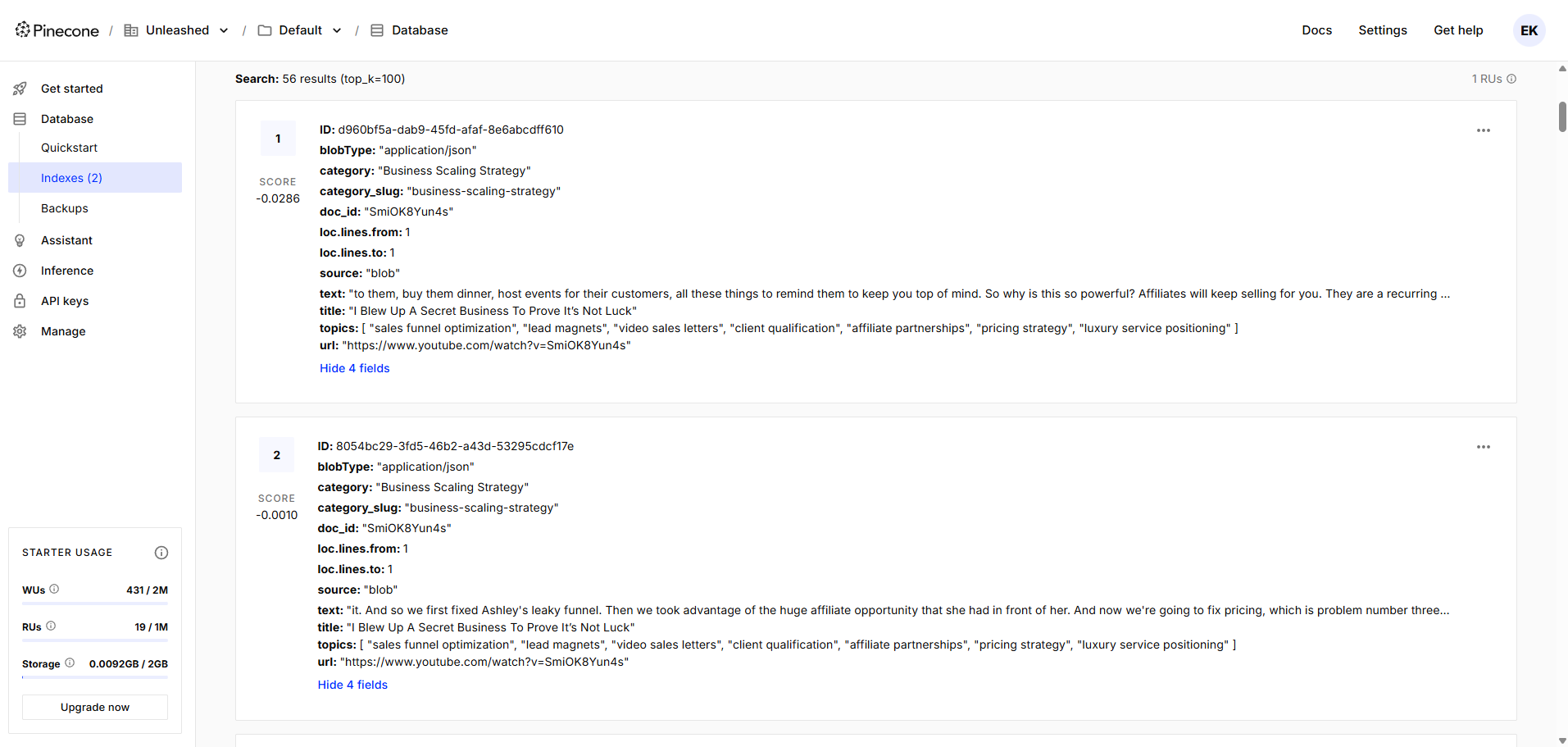
Embedding generation via OpenAI API, converting each chunk into a high-dimensional vector representation
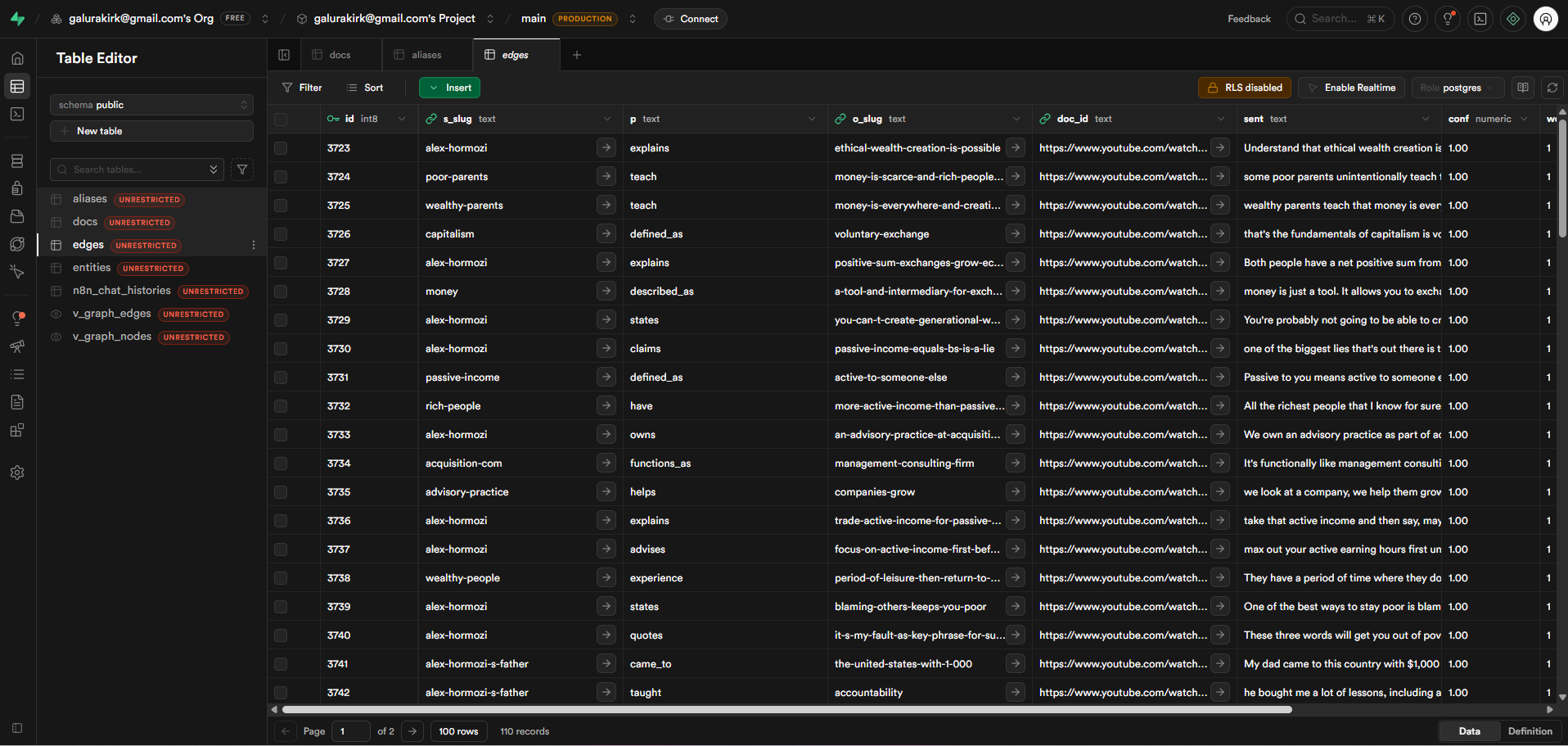
Structured metadata attachment — each vector stored with doc_id, source, category, topic keywords, and chunk index for precise filtering
Automated upsert into Pinecone with duplicate detection and conflict resolution
Error handling for API rate limits, malformed payloads, and failed uploads — with retry logic and failure logging for auditability
✅ THE RESULT
The workflow transformed a static document library into a live, queryable semantic knowledge base. Retrieval switched from keyword matching to context-aware semantic search, dramatically improving result relevance. The pipeline processed large document batches automatically with no manual steps, and the structured metadata layer enabled precise filtering in downstream retrieval workflows — setting up the RAG agent in Case Study 3 to deliver accurate, grounded answers.